

Ijraset Journal For Research in Applied Science and Engineering Technology
From Text to Recommendations: How Vector Databases are Revolutionizing Personalized Content Delivery
Authors: Satyanand Kale
DOI Link: https://doi.org/10.22214/ijraset.2024.59852
Certificate: View Certificate
Abstract
Effective similarity search and retrieval are now possible thanks to vector databases, which have become a potent tool for organizing and searching high-dimensional data. This article provides a thorough examination of vector databases, their underlying theories, and their applications across a range of industries. In handling complex data types, we address the significance of vector representation and emphasize the benefits of vector databases over traditional databases [1]. The article explores the process of creating a vector database, highlighting the critical function of indexing strategies such as IVF (Inverted File Indexing) and HNSW (Hierarchical Navigable Small World) in guaranteeing the effectiveness and precision of searches [2]. In addition, we discuss the problems caused by the curse of dimensionality and offer solutions to lessen its effects on nearest neighbor searches [3]. The piece delves deeper into hosted vector database options, emphasizing AWS OpenSearch and its vector search features. We demonstrate how vector databases can revolutionize recommendation systems by facilitating the delivery of tailored content and improving user interaction [4]. The paper ends with a discussion of potential future research areas, such as improvements in indexing methods, deep learning integration, and scalability problems in large-scale vector databases. The goal of this work is to offer a useful resource to researchers and practitioners who want to use vector databases to take advantage of similarity search\'s powerful capabilities.
Introduction

I. INTRODUCTION
The need for more effective and efficient techniques of data management and retrieval has grown in recent years due to big data's explosive growth and the complexity of digital content. The high dimensionality and unstructured nature of contemporary data types, like text, audio, and images, frequently present challenges for traditional databases, which depend on exact matching and structured query languages [5]. Vector databases, a novel method of storing and searching data based on the concepts of similarity and vector representation, have emerged as a result of this limitation. Vector databases are becoming more popular among researchers and businesses because they can use similarity search to its fullest in many areas, such as recommendation systems, image and video retrieval, natural language processing, and finding strange things [6].
Vector databases provide quick and precise access to related items by encoding complex data as high-dimensional vectors and utilizing sophisticated indexing techniques. This creates new opportunities for personalized content delivery, semantic search, and pattern recognition. Finding documents that are pertinent to a given query is the main objective of the information retrieval field, which is where the idea of similarity search originated [7]. But conventional methods of information retrieval, like keyword-based searches, frequently fall short of capturing the relationships and semantic significance of the data. Vector databases represent data in a continuous, high-dimensional space where proximity between vectors denotes similarity [8] in order to overcome this restriction. The vector representation of data, which is often accomplished through machine learning methods like deep learning and neural networks, is the cornerstone of vector databases [9]. By mapping raw data into a dense, continuous vector space, where similar items are mapped closer together, these models learn how to map data. Vector databases, which encode the semantic information and relationships within the data into the vector representations, enable a more contextualized and nuanced understanding of similarity. Vector databases have a lot of potential, but they also have a lot of problems, especially with scaling and the curse of dimensionality [10]. It becomes difficult to identify significant nearest neighbors when the vector space's volume grows exponentially with the number of dimensions. To overcome these difficulties and guarantee accurate and efficient similarity search in high-dimensional spaces, researchers and practitioners have been actively creating and improving indexing techniques, such as HNSW and IVF [11].
With an emphasis on their foundational ideas, building blocks, and applications, this article seeks to present a thorough introduction to vector databases. In-depth discussions of the difficulties and tactics involved in performance optimization are included, along with a comparison of hosted vector database options with an emphasis on AWS OpenSearch. Moreover, we address the directions for future research and new developments in the field while highlighting the transformative power of vector databases across a number of domains, especially recommendation systems. Readers will have a thorough understanding of vector databases by the end of this article, as well as their advantages over traditional databases and potential to transform personalized content delivery and similarity search. Our goal is to provide decision-makers, practitioners, and researchers with the information and understanding needed to leverage vector databases in their fields and spur innovation in the big data and machine learning eras.
II. FUNDAMENTALS OF VECTOR DATABASES
A. Vector Representation of high-Dimensional Data
The basic idea behind vector databases is to represent high-dimensional data—like text, audio, and images—as dense, continuous vectors in a mathematical space [12]. The process of mapping the raw data into a fixed-length numerical vector that encapsulates its key properties and semantic information is called vector embedding, also referred to as feature extraction. The vector representation enables efficient data storage, comparison, and retrieval based on similarity in the vector space.
The type of data and the intended characteristics of the vector space influence the selection of the selection of the vector embedding technique. Word embedding models, such as Word2Vec [13] and GloVe [14], for instance, are used in natural language processing to map words into a continuous vector space where semantically related words are grouped together. Convolutional neural networks (CNNs), which are popular in computer vision, extract feature vectors, or visual patterns and semantic content, from images [15].
In vector databases, the dimensionality of the vector space is an important factor. Higher-dimensional vectors require more storage space and computational power, but they can capture more detailed and subtle information about the data. The ideal trade-off between representational power and efficiency is a topic of ongoing study for vector databases.
B. Similarity Search and Nearest Neighbor Queries
Nearest neighbor and similarity searches are at the heart of vector databases' operations. Using their vector representations as a basis, a similarity search finds the items that are most similar to a given query item. This is usually accomplished by calculating the distance or similarity using metrics like Euclidean distance, cosine similarity, or Hamming distance between the query vector and the vectors in the database [16].
Nearest neighbor queries, also referred to as k-NN queries, return the k items in the vector space that are closest to the query vector [17]. Many vector database applications, including content-based retrieval, anomaly detection, and recommendation systems, rely on these fundamental queries. Highly relevant and customized results can be obtained from vector databases by determining the closest neighbors of a query item. Vector databases use a variety of indexing techniques to efficiently organize the vector space into a searchable structure, enabling the execution of nearest neighbor and similarity search queries. These methods, which include HNSW, IVF, and LSH, are designed to make similarity searches fast and scalable even in large-scale databases by narrowing the search space and quickening the retrieval process.
C. Advantages of Vector Databases over Traditional Databases
In comparison to traditional databases, vector databases have various significant advantages when managing unstructured and high-dimensional data. These advantages include:
- Semantic Similarity: By capturing the connections and semantic relationships between data points, vector databases make it possible to produce search results that are more pertinent and contextual. The underlying semantic connections within the data are frequently difficult for traditional databases to find because they rely so heavily on exact matching and structured queries.
- Scalability: Vector databases are made to grow with the volume and complexity of data in an effective manner [18]. Their utilization of distributed computing frameworks and specialized indexing techniques allows them to efficiently handle large datasets and deliver quick similarity search results.
- Flexibility: Without requiring explicit schema definitions or inflexible data structures, vector databases can handle a wide range of data types, including text, images, audio, and video [19]. This flexibility facilitates the integration of heterogeneous data sources and more natural and intuitive data representation.
- Adaptability: Vector databases are easily able to adjust to changing data distributions and to new data points [20]. The vector representations can be updated incrementally as new data is added, negating the need for expensive database migrations or redesigns.
- Compatibility with Machine Learning: Vector databases work well when combined with algorithms and models for machine learning. Deep learning models are frequently the source of the vector representations used in vector databases, allowing for smooth integration and the efficient use of neural networks for data analysis and similarity searches.
For applications requiring individualized recommendations, high-dimensional, unstructured data handling, and effective similarity search, vector databases are a compelling option because of these benefits. Vector databases have the potential to be a key tool in leveraging similarity and enabling innovative data-driven applications as data volume and complexity increase.
III. BUILDING A VECTOR DATABASE
A. Choosing an Effective Vector Indexing Technique
Choosing an appropriate indexing technique that can handle high-dimensional vectors and facilitate quick similarity searches is essential to building an effective and scalable vector database. By structuring the vector space into a searchable framework, vector indexing techniques minimize the number of comparisons required to identify the closest neighbors. In vector databases, HNSW (Hierarchical Navigable Small World graphs) and IVF (Inverted File Indexing) are two common indexing strategies.
B. HNSW (Hierarchical Navigable Small World graphs)
Using graph-based indexing, HNSW creates a hierarchical structure of connected nodes, each of which represents a portion of the vector space. By repeatedly adding new nodes and joining them to preexisting nodes according to how similar they are, the graph is built. Because HNSW is hierarchical, an effective top-down search is possible, with the search being refined gradually in the lower layers after beginning in the upper layers.
HNSW has a number of benefits, such as its adaptability to different distance metrics, support for dynamic updates, and capacity to handle high-dimensional vectors [21]. It has been demonstrated to perform better than alternative indexing methods in terms of accuracy and search speed, especially for large-scale datasets [22]. Open-source vector database libraries like Annoy and Faiss make extensive use of HNSW [23].
C. IVF (Inverted File Indexing)
IVF is an indexing method that manages high-dimensional vectors by modifying the inverted file structure, which is frequently used in text retrieval [24]. A set of Voronoi cells, each represented by a centroid vector, make up the vector space used in in vitro fertilization (IVF). The closest centroid is then given the vectors, creating an inverted index that links every centroid to its corresponding vectors.
In the process of similarity search, IVF finds the query vector's closest centroids first, and then it looks for the closest neighbors by searching through the corresponding inverted lists [25].
IVF increases search efficiency by reducing the number of comparisons by restricting the search to a portion of the vector space. IVF has been used in conjunction with other strategies, like product quantization [26], to further optimize search performance. It is especially useful for large-scale datasets.
D. Importance Of Proper Indexing For Search Efficiency And Precision
In vector databases, achieving high search efficiency and precision requires proper indexing. Similarity search without indexing would have a linear search complexity that does not scale well with the size of the dataset because it would have to compare the query vector to every vector in the database very carefully [27]. Indexing methods like HNSW and IVF help solve this problem by organizing the vector space in a way that makes it easy to search. This makes sublinear searches easier and faster retrieval of nearest neighbors possible. It is also important to have indexing strategies to keep search results accurate, especially in spaces with a lot of dimensions, where the "dimensionality curse" can make it harder for similarity metrics to tell the difference between things. Indexing techniques can reduce the effects of dimensionality and guarantee that the retrieved nearest neighbors are actually similar to the query vector by carefully dividing the vector space and choosing representative centroids.
E. Steps Involved in Building a Vector Database
Creating a vector database requires the following crucial steps:
- Preparing the Data: The initial stage involves converting the unprocessed data into a format that is appropriate for vector embedding. This could entail activities like feature extraction, data normalization, and cleaning [28].
- The next step is to run the preprocessed data through a vector embedding model, like a deep neural network. This creates dense, fixed-length vectors that hold the semantic information of the data. The type of data and the intended vector space properties determine which embedding model is best.
- Indexing: After obtaining the vectors, the vector space is arranged into a searchable structure using an appropriate indexing technique (e.g., HNSW or IVF). To maximize search efficiency and precision, indexing parameters are adjusted, such as the number of layers in HNSW or the number of centroids in IVF.
- Storage and retrieval: The database management system that houses the indexed vectors enables the effective storage and retrieval of high-dimensional data [29]. An interface for similarity search queries should be available in the database, enabling users to enter a query vector and get the closest neighbors.
- Assessment and improvement: The vector database's functionality is assessed through the use of pertinent metrics, including scalability, accuracy, and search speed. Iterative improvements and optimizations can be made to the vector embedding model, indexing strategy, and database parameters based on the evaluation results.
Developers can use these steps to create a vector database that offers high performance and gives their applications powerful similarity search capabilities. They should also choose appropriate techniques at each stage.
IV. CHALLENGES IN VECTOR DATABASES
A. The Curse of Dimensionality
The "curse of dimensionality," or the phenomenon wherein similarity search performance declines with increasing vector dimensionality, is a major challenge for vector databases. This problem stems from the intrinsic characteristics of high-dimensional spaces and has significant effects on vector databases' efficacy and efficiency.
B. Definition and Implications
Richard Bellman first used the phrase "curse of dimensionality" in the 1960s to characterize the exponential rise in volume that results from extending a mathematical space's dimensions [30]. Regarding vector databases, it means that when the number of dimensions rises, the space's volume grows so quickly that the data becomes scarce and the meaning of proximity and distance is diminished. The curse of dimensionality has two consequences. First, it has an impact on the computational complexity of similarity search algorithms because finding the nearest neighbors requires an exponentially large number of distance calculations [31]. Second, it reduces the ability of similarity measures to discriminate between relevant and irrelevant neighbors by lessening the contrast between the nearest and farthest points [32].
C. Impact on Nearest Neighbor Search
A key function in vector databases, nearest neighbor search performance, is directly impacted by the curse of dimensionality. The number of data points needed to maintain a given degree of coverage and density in the space grows exponentially with increasing dimensionality [33]. This implies that it gets harder to determine who the actual nearest neighbors are as the average distance between any two points gets closer.
In addition, the dimensionality curse has an impact on indexing structures that speed up nearest neighbor searches. As dimensionality rises, traditional indexing methods like k-d trees and R-trees experience exponential growth in both node count and tree depth [34]. As a result, there is a phenomenon called the "dimensionality curse," wherein these indexing structures perform no better than a linear scan of the whole dataset [35].
D. Strategies for Mitigating the Curse of Dimensionality
Many approaches have been put forth, with an emphasis on effective indexing strategies and dimensionality reduction techniques, to lessen the negative effects of the curse of dimensionality on vector databases.
E. Efficient Indexing of high-dimensional Vectors
Overcoming the curse of dimensionality requires the development of effective indexing strategies for high-dimensional vectors. Using approximate nearest neighbor (ANN) algorithms is one method that offers notable speedups in search time in exchange for a small loss of accuracy [36]. A well-liked ANN method called "locality-sensitive hashing" (LSH) allows for sublinear search times by mapping similar vectors to the same hash bucket with high probability.
Using hierarchical indexing structures, like HNSW (Hierarchical Navigable Small World) graphs, is an additional strategy. These structures arrange the vectors into a multi-level hierarchy according to how similar they are. HNSW can effectively reduce the search space and locate the closest neighbors by moving through the hierarchy from coarse to fine levels without thoroughly comparing the query vector to every vector in the database.
F. Dimensionality Reduction Techniques
The goal of dimensionality reduction techniques is to lessen the negative effects of dimensionality by projecting high-dimensional vectors into a lower-dimensional space while maintaining their fundamental characteristics. A popular method for reducing the linear dimensionality of data is principal component analysis (PCA), which projects the vectors onto the orthogonal directions of the maximum variance in the data [37].
In recent times, there has been an increase in popularity of non-linear dimensionality reduction techniques like UMAP (Uniform Manifold Approximation and Projection) and t-SNE (t-Distributed Stochastic Neighbor Embedding) [38]. By maintaining the local neighborhoods and divergences in the lower-dimensional space, these methods seek to capture the intrinsic structure of the data.
Vector databases can effectively lessen the effects of the curse of dimensionality by implementing dimensionality reduction techniques, which will increase the effectiveness and precision of similarity searches. It is crucial to remember, though, that dimensionality reduction frequently necessitates balancing the degree of compression with the preservation of the original data structure [39].
To sum up, vector databases face a great deal of difficulties due to the curse of dimensionality, which impacts both the computational complexity and the ability of similarity searches to discriminate. Vector databases can lessen the effects of the curse of dimensionality and provide high-performance similarity searches in high-dimensional spaces by utilizing effective indexing strategies and dimensionality reduction techniques.
V. HOSTED VECTOR DATABASE SOLUTIONS
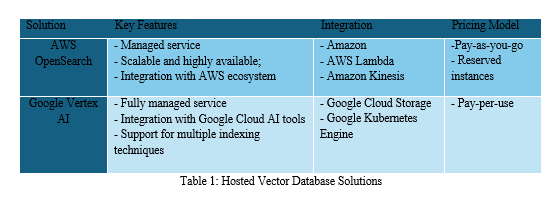
A. AWS OpenSearch
It is simple to set up, run, and grow OpenSearch clusters in the cloud with Amazon Web Services' fully managed AWS OpenSearch service [40]. Website search, real-time application monitoring, log analytics, and other use cases are all supported by the open-source search and analytics engine OpenSearch.
B. Overview and Features
AWS OpenSearch is based on the open-source OpenSearch project, which combines Elasticsearch and Kibana [41]. It offers a range of features and tools for real-time indexing, searching, and data analysis on massive volumes. Some of the key features of AWS OpenSearch include [42]:
- Clusters that are fully managed, have high availability, and automatically scale
- Integration of access control and security features with AWS
- Integrated dashboarding and data visualization features with OpenSearch Dashboards
- a large variety of data types are supported, including unstructured, semi-structured, and structured data
- Support for advanced query languages and full-text search
- Real-time indexing and data intake
C. Vector Search Capabilities
Recently, vector search was supported by AWS OpenSearch, allowing users to search for similarity in high-dimensional vectors. Applications that work with dense vector representations, like those produced by embedding techniques or machine learning models, will find this feature especially helpful.
AWS OpenSearch's vector search allows users to:
- Effectively index and store high-dimensional vectors
- To determine which vectors are most similar to a given query vector, use the nearest neighbor search method.
- Use the Euclidean distance or cosine similarity as the similarity metric.
- For hybrid search workflows, combine traditional text search with vector search.
Users must create an index with a vector field type and specify the vectors' dimensions in order to use vector search in AWS OpenSearch [43]. They can then run a nearest neighbor search on the vector fields using the knn query type.
D. Integration with other AWS Services
The smooth integration of AWS OpenSearch with other AWS services is one of the main benefits of using it. This enables customers to create end-to-end solutions that combine other AWS services with the strength of vector search.
OpenSearch can be integrated with a number of AWS services, such as [44]:
- Real-time data streaming and ingestion using Amazon Kinesis
- Serverless computing and data processing with AWS Lambda
- Amazon S3 for backup and data storage
- Amazon Glue for ETL and data integration processes
- Machine learning and model deployment with Amazon SageMaker
Through these integrations, users can combine the capabilities of vector search with other data processing and analysis services available in the AWS ecosystem to create robust and scalable applications.
E. Comparison with other Hosted Vector Database Solutions
Although AWS OpenSearch is a well-liked option for hosted vector search, there are other products on the market with comparable features. Among the noteworthy substitutes are:
- Algolia: With its Algolia AI offering, Algolia, a fully managed search platform, supports vector search. It offers features like automatic model selection and hyperparameter tuning, as well as an intuitive interface and API for vector indexing and searching.
- Pinecone: Dedicated to vector databases, Pinecone provides both on-premises and hosted solutions [45]. In addition to features like real-time updates, horizontal scaling, and support for multiple similarity metrics, it offers a straightforward API for vector indexing and searching.
- Milvus: Zilliz Cloud offers an open-source vector database that can be used as a managed service or self-hosted [46]. In addition to features like distributed indexing, hybrid search, and integration with well-known machine learning frameworks, it provides high performance and scalability for vector search workloads.
Users should compare AWS OpenSearch with these alternatives based on features like price, integration with existing infrastructure and workflows, scalability, performance, and ease of use. The advantages of AWS OpenSearch include its close integration with the AWS ecosystem and its versatility in handling workloads beyond vector search for analytics and search.
The final decision regarding a hosted vector database solution is made in light of the application's unique needs and limitations as well as the development team's experience and familiarity with various platforms and technologies.
VI. APPLICATIONS AND USE CASES

A. Recommendation Systems
Recommendation systems are now commonplace in many industries, including entertainment and e-commerce. Personalized recommendations are made possible by vector databases, which harness the potential of similarity searches. Recommendation engines can effectively identify the most relevant items for each user based on their similarity scores by encoding user preferences and item features as high-dimensional vectors [47].
B. Personalized Content and Product Recommendations
Highly customized content and product recommendation systems can be developed with the use of vector databases. These systems recommend items that closely match user preferences by analyzing the degree of similarity between item feature vectors and user behavior vectors. For example, Netflix uses a vector-based approach to recommend movies and TV shows to its users based on their viewing history and ratings [48]. In a similar vein, Amazon's product recommendation system makes use of vector similarity to determine which products users are likely to find interesting based on their prior purchases and browsing activity [49].
C. Enhancing user Experience Through Similarity-based Suggestions
Vector database-powered similarity-based recommendations have the potential to greatly improve the user experience on a variety of platforms. Vector embeddings are used by the well-known music streaming service Spotify to generate customized playlists and suggest songs that align with users' musical preferences [50]. Twitter is one of the social media platforms that uses vector representations to recommend tweets and accounts to follow based on user interactions and interests [51]. These personalized recommendations keep users interested and satisfied, which increases user retention and loyalty. Traditional keyword-based search engines frequently miss the visual similarity between images or videos.
D. Image and Video Search
Content-based retrieval made possible by vector databases has revolutionized image and video search. Traditional keyword-based search engines frequently miss the visual similarity between images or videos. Vector databases are able to efficiently perform similarity searches to find visually similar images or videos by representing visual content as vectors using deep learning techniques such as convolutional neural networks (CNNs) [52]. Reverse image search and content-based video retrieval are just two of the many uses for this. Notable instances of vector database-driven image retrieval systems are Google's Image Search and Pinterest's visual search function [53, 54].
E. Natural Language Processing and Semantic Search
Because dense vectors can represent words, sentences, and documents, vector databases have revolutionized semantic search and natural language processing (NLP). Word embeddings, like Word2Vec and GloVe [55], effectively facilitate similarity-based retrieval by capturing the semantic relationships between words. Sentence and document embeddings, such as Doc2Vec [56] and BERT, enable higher-level semantic search by making it simpler to retrieve pertinent passages or documents based on how semantically similar they are to a given query. Semantic search engines, chatbots, and Q&A platforms run on vector databases, which improve the precision and effectiveness of information retrieval.
F. Fraud Detection and Anomaly Detection
Vector databases use similarity searches to their advantage in fraud and anomaly detection applications. By representing transactions or system logs as vectors [57], anomaly detection algorithms can find patterns that do not make sense or outliers that are very different from the norm. By comparing the vector representations of suspicious transactions with recognized fraudulent patterns, vector databases aid in the detection of financial fraud [58]. Similar to this, by comparing traffic vectors with past data, vector databases can help in the identification of anomalous network traffic in network intrusion detection [59]. Vector databases are an important tool in the fight against fraud and for maintaining system security because of their quick and precise similarity search capabilities.
VII. FUTURE DIRECTIONS AND RESEARCH
A. Advancements In vector Indexing Techniques
The development of sophisticated vector indexing techniques is still a vital area of research because of the growing demand for effective similarity searches in high-dimensional spaces. One of the more recent developments is the use of learned indexes, which use machine learning to optimize index structures according to the dataset properties. To achieve high efficiency and accuracy, hybrid indexing approaches that combine the best features of various indexing techniques—for example, by combining graph-based and quantization-based methods—represent a promising new direction. Moreover, more efficient and customized solutions for particular applications may result from the indexing process's integration of domain-specific knowledge and constraints.
B. Scalability and Distributed Computing for large-scale Vector Databases
The scalability of vector databases becomes an urgent challenge with the rapid growth of data in multiple domains. Massive vector datasets have been processed and stored across machine clusters using distributed computing frameworks like Hadoop and Apache Spark [60]. However, there are extra challenges in designing distributed vector database systems because of the peculiarities of vector data and the requirement for an effective similarity search. The main goals of research are to create fault-tolerant and scalable architectures, effective load-balancing and data partitioning techniques, and communication protocols that are optimized for distributed similarity search. Cloud computing platforms like Amazon Web Services (AWS) and Google Cloud Platform (GCP) can be integrated with vector databases to provide opportunities for elastic scalability and cost-effective deployment.
C. Integration with Deep Learning Models and Architectures
An increasing number of people are interested in combining deep learning models and architectures with vector databases as a result of the success of deep learning in numerous fields, including computer vision and natural language processing. Compact and semantically meaningful vector representations of complex data, including text, images, and videos, can be learned through deep learning techniques. The effective indexing and searching of these learned representations through the use of vector databases makes applications like content-based retrieval and recommendation possible. Additionally, it is possible to effortlessly incorporate similarity search capabilities into end-to-end deep learning pipelines by integrating vector databases with deep learning frameworks like TensorFlow and PyTorch [61]. Additionally, research is being done to create specialized hardware accelerators, like GPUs and TPUs, to speed up vector database operations and deep learning model inference and training.
D. Emerging Applications and Domains
The potential of vector databases is being investigated in a number of newly emerging domains, going beyond conventional application areas. The use of vector databases for the analysis and searching of sizable medical datasets, including genetic data, electronic health records, and medical images, has made personalized medicine and drug discovery possible in the healthcare industry. Within the field of cybersecurity, vector databases can be utilized to effectively search through enormous volumes of network logs and security events in order to detect and analyze threats in real time. Vector databases are used in scientific fields like computational biology, where they are helpful for searching and analyzing large datasets of protein structures and gene expressions [62]. As the adoption of vector databases continues to grow, it is expected that new and innovative applications will emerge across various domains, driving further research and development in this field.
Conclusion
As a potent tool for organizing and searching high-dimensional data, vector databases have become widely used in many different fields. These databases have revolutionized the way we interact with and gain insights from complex data types, like text, audio, and image, by utilizing the power of similarity search. We have discussed the basic ideas behind vector databases, as well as their main features and implementation difficulties, in this article. We have covered the vital role that efficient vector indexing techniques play in providing quick and precise similarity searches, and we have highlighted well-liked methods such as HNSW and IVF. We have also explored hosted vector database solutions, emphasizing AWS OpenSearch and its smooth integration with the AWS ecosystem in particular. The transformative potential of vector databases in applications like fraud detection, natural language processing, image and video search, and recommendation systems has been demonstrated in this article. It is clear that vector databases will continue to be essential in the big data and machine learning eras as we look to the future. Further developments in vector indexing techniques, as well as growing scalability and distributed computing capabilities, will make it possible to create vector database systems that are even more advanced and effective. Furthermore, there are a lot of exciting opportunities for knowledge discovery and wise decision-making when vector databases are integrated with deep learning models and architectures. The potential use cases for vector databases will grow as new applications and domains develop further, spurring innovation and upending entire industries. To sum up, vector databases mark a critical turning point in our understanding of the potential of high-dimensional data. We can anticipate ground-breaking developments that will completely change how we store, search for, and analyze complex data as research and development in this area continues. There is no denying that vector databases have a bright future ahead of them. It is up to the scientific community and business executives to work together to push the envelope and discover new avenues for data-driven insights and decision-making.
References
[1] Musgrave, K., Belongie, S., & Lim, S. N. (2020). A metric learning reality check. In European Conference on Computer Vision (pp. 681-699). Springer, Cham. https://doi.org/10.1007/978-3-030-58452-8_40 [2] Malkov, Y. A., & Yashunin, D. A. (2020). Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(4), 824-836. https://doi.org/10.1109/TPAMI.2018.2889473 [3] Aumüller, M., Bernhardsson, E., & Faithfull, A. (2020). ANN-benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Information Systems, 87, 101374. https://doi.org/10.1016/j.is.2019.02.006 [4] Zhang, S., Yao, L., Sun, A., & Tay, Y. (2019). Deep learning based recommender system: A survey and new perspectives. ACM Computing Surveys (CSUR), 52(1), 1-38. https://doi.org/10.1145/3285029 [5] Aghayev, A., Shafaei, M., & Desnoyers, P. (2022). Towards a General-Purpose Query Engine for Big Vectors. Proceedings of the VLDB Endowment, 15(4), 791-803. https://doi.org/10.14778/3503585.3503589 [6] Johnson, J., Douze, M., & Jégou, H. (2021). Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3), 535-547. https://doi.org/10.1109/TBDATA.2019.2921572 [7] Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to information retrieval. Cambridge university press. https://nlp.stanford.edu/IR-book/ [8] Muja, M., & Lowe, D. G. (2014). Scalable nearest neighbor algorithms for high dimensional data. IEEE transactions on pattern analysis and machine intelligence, 36(11), 2227-2240. https://doi.org/10.1109/TPAMI.2014.2321376 [9] Bengio, Y., Courville, A., & Vincent, P. (2013). Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence, 35(8), 1798-1828. https://doi.org/10.1109/TPAMI.2013.50 [10] Pestov, V. (2000). On the geometry of similarity search: Dimensionality curse and concentration of measure. Information Processing Letters, 73(1-2), 47-51. https://doi.org/10.1016/S0020-0190(99)00156-8 [11] Wang, J., Shen, H. T., Song, J., & Ji, J. (2014). Hashing for similarity search: A survey. arXiv preprint arXiv:1408.2927. https://arxiv.org/abs/1408.2927 [12] Guo, C., Berkhahn, F., Vajda, P., & Neven, D. (2016). Entity embeddings for categorical variables. arXiv preprint arXiv:1604.06737. https://arxiv.org/abs/1604.06737 [13] Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781. https://arxiv.org/abs/1301.3781 [14] Pennington, J., Socher, R., & Manning, C. D. (2014). GloVe: Global vectors for word representation. Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 1532-1543. https://aclanthology.org/D14-1162/ [15] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 1097-1105. https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html [16] Leskovec, J., Rajaraman, A., & Ullman, J. D. (2014). Mining of massive datasets. Cambridge university press. http://www.mmds.org/ [17] Gionis, A., Indyk, P., & Motwani, R. (1999). Similarity search in high dimensions via hashing. Proceedings of the 25th International Conference on Very Large Data Bases, 518-529. http://www.vldb.org/conf/1999/P49.pdf [18] Muja, M., & Lowe, D. G. (2014). Scalable nearest neighbor algorithms for high dimensional data. IEEE transactions on pattern analysis and machine intelligence, 36(11), 2227-2240. https://doi.org/10.1109/TPAMI.2014.2321376 [19] Johnson, J., Douze, M., & Jégou, H. (2021). Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3), 535-547. https://doi.org/10.1109/TBDATA.2019.2921572 [20] Aumüller, M., Bernhardsson, E., & Faithfull, A. (2020). ANN-benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Information Systems, 87, 101374. https://doi.org/10.1016/j.is.2019.02.006 [21] Baranchuk, D., Babenko, A., & Malkov, Y. (2018). Revisiting the inverted indices for billion-scale approximate nearest neighbors. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 202-216). https://doi.org/10.1007/978-3-030-01237-3_13 [22] u, C., Xiang, C., Wang, C., & Cai, D. (2019). Fast approximate nearest neighbor search with the navigating spreading-out graph. Proceedings of the VLDB Endowment, 12(5), 461-474. https://doi.org/10.14778/3303753.3303754 [23] Bernhardsson, E. (2015). Annoy: Approximate nearest neighbors in c++/python optimized for memory usage and loading/saving to disk. GitHub repository. https://github.com/spotify/annoy [24] Jégou, H., Douze, M., & Schmid, C. (2011). Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence, 33(1), 117-128. https://doi.org/10.1109/TPAMI.2010.57 [25] Babenko, A., & Lempitsky, V. (2015). The inverted multi-index. IEEE transactions on pattern analysis and machine intelligence, 37(6), 1247-1260. https://doi.org/10.1109/TPAMI.2014.2361319 [26] Ge, T., He, K., Ke, Q., & Sun, J. (2014). Optimized product quantization. IEEE transactions on pattern analysis and machine intelligence, 36(4), 744-755. https://doi.org/10.1109/TPAMI.2013.240 [27] Indyk, P., & Motwani, R. (1998). Approximate nearest neighbors: Towards removing the curse of dimensionality. In Proceedings of the thirtieth annual ACM symposium on Theory of computing (pp. 604-613). https://doi.org/10.1145/276698.276876 [28] Marsland, S. (2014). Machine learning: an algorithmic perspective. Chapman and Hall/CRC. https://www.taylorfrancis.com/books/9781351382175 [29] ao, Y., Yi, K., Sheng, C., & Kalnis, P. (2009). Quality and efficiency in high dimensional nearest neighbor search. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of data (pp. 563-576). https://doi.org/10.1145/1559845.1559902 [30] Bellman, R. (1966). Dynamic programming. Science, 153(3731), 34-37. https://doi.org/10.1126/science.153.3731.34 [31] Beyer, K., Goldstein, J., Ramakrishnan, R., & Shaft, U. (1999). When is \"nearest neighbor\" meaningful?. In International conference on database theory (pp. 217-235). Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-49257-7_15 [32] Aggarwal, C. C., Hinneburg, A., & Keim, D. A. (2001). On the surprising behavior of distance metrics in high dimensional space. In International conference on database theory (pp. 420-434). Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-44503-X_27 [33] Marimont, R. B., & Shapiro, M. B. (1979). Nearest neighbour searches and the curse of dimensionality. Journal of the Institute of Mathematics and its Applications, 24(1), 59-70. https://doi.org/10.1093/imamat/24.1.59 [34] Böhm, C., Berchtold, S., & Keim, D. A. (2001). Searching in high-dimensional spaces: Index structures for improving the performance of multimedia databases. ACM Computing Surveys (CSUR), 33(3), 322-373. https://doi.org/10.1145/502807.502809 [35] Berchtold, S., Böhm, C., Keim, D. A., & Kriegel, H. P. (1997). A cost model for nearest neighbor search in high-dimensional data space. In Proceedings of the sixteenth ACM SIGACT-SIGMOD-SIGART symposium on Principles of database systems (pp. 78-86). https://doi.org/10.1145/263661.263671 [36] Andoni, A., & Indyk, P. (2008). Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. Communications of the ACM, 51(1), 117-122. https://doi.org/10.1145/1327452.1327494 [37] Jolliffe, I. T., & Cadima, J. (2016). Principal component analysis: a review and recent developments. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 374(2065), 20150202. https://doi.org/10.1098/rsta.2015.0202 [38] McInnes, L., Healy, J., & Melville, J. (2018). UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426. https://arxiv.org/abs/1802.03426 [39] Gisbrecht, A., & Schleif, F. M. (2015). Metric and non-metric proximity transformations at linear costs. Neurocomputing, 167, 643-657. https://doi.org/10.1016/j.neucom.2015.04.017 [40] Amazon Web Services. (2021). Amazon OpenSearch Service. https://aws.amazon.com/opensearch-service/ [41] OpenSearch. (2021). OpenSearch Documentation. https://opensearch.org/docs/latest/ [42] Amazon Web Services. (2021). Amazon OpenSearch Service Features. https://aws.amazon.com/opensearch-service/features/ [43] Amazon Web Services. (2021). Working with Vector Fields and k-NN Search in Amazon OpenSearch Service. https://docs.aws.amazon.com/opensearch-service/latest/developerguide/knn.html [44] Amazon Web Services. (2021). Integrating Amazon OpenSearch Service with Other AWS Services. https://docs.aws.amazon.com/opensearch-service/latest/developerguide/integrations.html [45] Pinecone. (2021). Pinecone: The Vector Database for Machine Learning. https://www.pinecone.io/ [46] Zilliz. (2021). Milvus: An Open-Source Vector Database for Scalable Similarity Search. https://milvus.io/ [47] Linden, G., Smith, B., & York, J. (2003). Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Computing, 7(1), 76-80. https://doi.org/10.1109/MIC.2003.1167344 [48] Gomez-Uribe, C. A., & Hunt, N. (2015). The Netflix recommender system: Algorithms, business value, and innovation. ACM Transactions on Management Information Systems (TMIS), 6(4), 1-19. https://doi.org/10.1145/2843948 [49] Smith, B., & Linden, G. (2017). Two decades of recommender systems at Amazon.com. IEEE Internet Computing, 21(3), 12-18. https://doi.org/10.1109/MIC.2017.72 [50] Ciocca, S. (2017). How does Spotify know you so well? Medium. https://medium.com/s/story/spotifys-discover-weekly-how-machine-learning-finds-your-new-music-19a41ab76efe [51] Gupta, P., Goel, A., Lin, J., Sharma, A., Wang, D., & Zadeh, R. (2013). WTF: The who to follow service at Twitter. Proceedings of the 22nd International Conference on World Wide Web, 505-514. https://doi.org/10.1145/2488388.2488433 [52] Wan, J., Wang, D., Hoi, S. C. H., Wu, P., Zhu, J., Zhang, Y., & Li, J. (2014). Deep learning for content-based image retrieval: A comprehensive study. Proceedings of the 22nd ACM International Conference on Multimedia, 157-166. https://doi.org/10.1145/2647868.2654948 [53] Jing, Y., Liu, D., Kislyuk, D., Zhai, A., Xu, J., Donahue, J., & Tavel, S. (2015). Visual search at Pinterest. Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1889-1898. https://doi.org/10.1145/2783258.2788621 [54] Zhu, A., Gao, H., Lin, J., Shen, X., Lu, H., Shen, X., & Yang, Y. (2018). Deep learning for image-based large-scale video recommendation. arXiv preprint arXiv:1811.01668. https://arxiv.org/abs/1811.01668 [55] Pennington, J., Socher, R., & Manning, C. D. (2014). GloVe: Global vectors for word representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1532-1543. https://doi.org/10.3115/v1/D14-1162 [56] Le, Q., & Mikolov, T. (2014). Distributed representations of sentences and documents. Proceedings of the 31st International Conference on Machine Learning, 1188-1196. http://proceedings.mlr.press/v32/le14.html [57] Phua, C., Lee, V., Smith, K., & Gayler, R. (2010). A comprehensive survey of data mining-based fraud detection research. arXiv preprint arXiv:1009.6119. https://arxiv.org/abs/1009.6119 [58] Sudjianto, A., Nair, S., Yuan, M., Zhang, A., Kern, D., & Cela-Díaz, F. (2010). Statistical methods for fighting financial crimes. Technometrics, 52(1), 5-19. https://doi.org/10.1198/TECH.2010.07032 [59] Garcia-Teodoro, P., Diaz-Verdejo, J., Maciá-Fernández, G., & Vázquez, E. (2009). Anomaly-based network intrusion detection: Techniques, systems and challenges. Computers & Security, 28(1-2), 18-28. https://doi.org/10.1016/j.cose.2008.08.003 [60] Shvachko, K., Kuang, H., Radia, S., & Chansler, R. (2010). The Hadoop distributed file system. Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), 1-10. https://doi.org/10.1109/MSST.2010.5496972 [61] Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., ... & Chintala, S. (2019). PyTorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems, 32, 8024-8035. https://papers.nips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf [62] Stephens, Z. D., Lee, S. Y., Faghri, F., Campbell, R. H., Zhai, C., Efron, M. J., ... & Robinson, G. E. (2015). Big data: Astronomical or genomical? PLoS Biology, 13(7), e1002195. https://doi.org/10.1371/journal.pbio.1002195
Copyright
Copyright © 2024 Satyanand Kale. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET59852
Publish Date : 2024-04-05
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online